
Decision Tree Forests
Decision Tree Forest - Ensemble of Trees
A Decision Tree Forest is an ensemble (collection) of decision trees whose predictions are combined to make the overall prediction for the forest. A decision tree forest is similar to a TreeBoost model in the sense that a large number of trees are grown. However, TreeBoost generates a series of trees with the output of one tree going into the next tree in the series. In contrast, a decision tree forest grows a number of independent trees in parallel, and they do not interact until after all of them have been built.
Both TreeBoost and decision tree forests produce high accuracy models. Experiments have shown that TreeBoost works better with some applications and decision tree forests with others, so it is best to try both methods and compare the results.
Features of Decision Tree Forest Models:
- Decision tree forest models often have a degree of accuracy that cannot be obtained using a large, single-tree model. Decision tree forest models are among the most accurate models yet invented.
- Decision tree forest models are as easy to create as single-tree models. By simply setting a control button, you can direct DTREG to create a single-tree model or a decision tree forest model or a TreeBoost model for the same analysis.
- Decision tree forests use the out of bag data rows for validation of the model. This provides an independent test without requiring a separate data set or holding back rows from the tree construction.
- Decision tree forest models can handle hundreds or thousands of potential predictor variables.
- The sophisticated and accurate method of surrogate splitters is used for handling missing predictor values.
- The stochastic (randomization) element in the decision tree forest algorithm makes it highly resistant to over fitting.
- Decision tree forests can be applied to regression and classification models.
The primary disadvantage of decision tree forests is that the model is complex and cannot be visualized like a single tree. It is more of a “black box” like a neural network. Because of this, it is advisable to create both a single-tree and a decision tree forest model. The single-tree model can be studied to get an intuitive understanding of how the predictor variables relate, and the decision tree forest model can be used to score the data and generate highly accurate predictions.
How Decision Tree Forests Are Created
Here is an outline of the algorithm used to construct a decision tree forest:
Assume the full data set consists of N observations.
- Take a random sample of Nobservations from the data set with replacement (this is called “bagging”). Some observations will be selected more than once, and others will not be selected. On average, about 2/3 of the rows will be selected by the sampling. The remaining 1/3 of the rows are called the “out of bag (OOB)” rows. A new random selection of rows is performed for each tree constructed.
- Using the rows selected in step 1, construct a decision tree. Build the tree to the maximum size, and do not prune it. As the tree is built, allow only a subset of the total set of predictor variables to be considered as possible splitters for each node. Select the set of predictors to be considered as a random subset of the total set of available predictors. For example, if there are ten predictors, choose a random five as candidate splitters. Perform a new random selection for each split. Some predictors (possibly the best one) will not be considered for each split, but a predictor excluded from one split may be used for another split in the same tree.
- Repeat steps 1 and 2 a large number of times constructing a forest of trees.
- To “score” a row, run the row through each tree in the forest and record the predicted value (i.e., terminal node) that the row ends up in (just as you would score using a single-tree model). For a regression analysis, compute the average score predicted by all of the trees. For a classification analysis, use the predicted categories for each tree as “votes” for the best category, and use the category with the most votes as the predicted category for the row.
Decision tree forests have two stochastic (randomizing) elements: (1) the selection of data rows used as input for each tree, and (2) the set of predictor variables considered as candidates for each node split. For reasons that are not well understood, these randomizations along with combining the predictions from the trees significantly improve the overall predictive accuracy.
No Overfitting or Pruning
"Overfitting" is a problem in large, single-tree models where the model begins to fit noise in the data. When such a model is applied to data not used to build the model, the model does not perform well (i.e., it does not generalize well). To avoid this problem, single-tree models must be pruned to the optimal size. In nearly all cases, decision tree forests do not have a problem with overfitting, and there is no need to prune the trees in the forest. Generally, the more trees in the forest, the better the fit.
Internal Measure of Test Set (Generalization) Error
When a decision tree forest is constructed using the algorithm outlined above, about 1/3 of data rows are excluded from each tree in the forest. The rows that are excluded from a tree are called the “out of bag (OOB)” rows for the tree; each tree will have a different set of out-of-bag rows. Since the out of bag rows are (by definition) not used to build the tree, they constitute an independent test sample for the tree.
To measure the generalization error of the decision tree forest, the out of bag rows for each tree are run through the tree and the error rate of the prediction is computed. The error rates for the trees in the forest are then averaged to give the overall generalization error rate for the decision tree forest model.
There are several advantages to this method of computing generalization error: (1) all of the rows are used to construct the model, and none have to be held back as a separate test set, (2) the testing is fast because only one forest has to be constructed (as compared to V-fold cross-validation where additional trees have to be constructed).
Decision Tree Forest Property Page
DTREG can build three types of predictive models:
- Single tree models.
- TreeBoost models which consist of a series of trees that form an additive model.
- Decision Tree Forest models consisting of an ensemble of trees whose predictions are combined.
Decision tree forest models often can provide greater predictive accuracy than single-tree models, but they have the disadvantage that you cannot visualize them the way you can a single tree; decision tree forest models are more of a “black box”.
The decision tree forest option is available only in the Advanced and Enterprise versions of DTREG.
When you select the decision tree forest property page, you will see a screen like this:
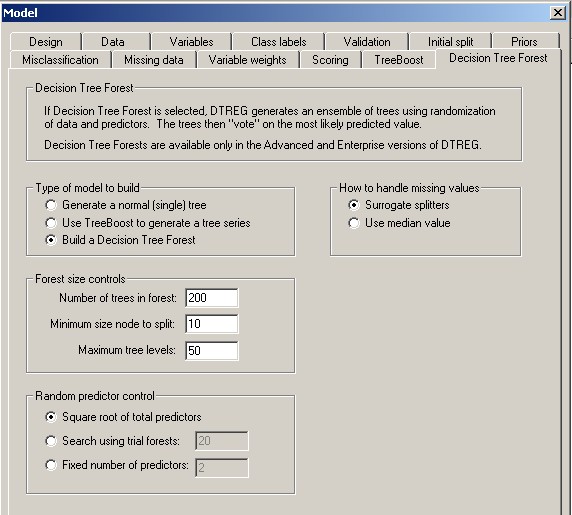
Type of model to build: - Select whether you want DTREG to create a single-tree model, a Decision Tree Forest or a TreeBoost model. If you select a single-tree model or a TreeBoost model all of the other controls on this screen will be disabled.
Forest size controls
Generally, the larger a decision tree forest is, the more accurate the prediction. There are two types of size controls available (1) the number of trees in the forest and (2) the size of each individual tree.
Number of trees in forest - This specifies how many trees are to be constructed in the decision tree forest. It is recommended that a minimum value of 100 be used.
Minimum size node to split – A node in a tree in the forest will not be split if it has fewer than this number of rows in it.
Maximum tree levels – Specify the maximum number of levels (depth) that each tree in the forest may be grown to. Some research indicates that it is best to grow very large trees, so the maximum levels should be set large and the minimum node size control would limit the size of the trees.
Random Predictor Control
When a tree is constructed in a decision tree forest, a random subset of the predictor variables are selected as candidate splitters for each node. The controls in this group set how many candidate predictors are considered as splitters for each node.
Square root of total predictors – If you select this option, DTREG will use the square root of the number of total predictor variables as the candidates for each node split. Leo Breiman recommends this as a default setting.
Search using trial forests – If you select this option, DTREG will built a set of trial decision tree forests using a different numbers of predictors and determine the optimal number of predictors to minimize the misclassification error. When doing the search, DTREG starts with 2 predictors and checks each possible number of predictors in steps of 2 up to but not including the total number of predictors. Once the optimal number of predictors is determined from the trial runs, that number is used to build the final decision tree forest. Clearly this method involves more computation than the other methods since multiple tree forests must be constructed. To save time, you can specify in the box on the option line a smaller number of trees in the trial forest than in the final forest.
Once the optimal number of predictors is determined, it is shown as the value with “Fixed number of predictors”, so you can select that option for subsequent runs without having to repeat the search.
Fixed number of predictors – If you select this option, you can specify exactly how many predictors you want DTREG to use as candidates for each node split.
How to Handle Missing Values
Surrogate splitters – If this option is selected, DTREG will compute the association between the primary splitter selected for a node and all other predictors including predictors not considered as candidates for the split. If the value of the primary predictor variable is missing for a row, DTREG will use the best surrogate splitter whose value is known for the row. Use the Missing Data property page to control whether DTREG always computes surrogate splitters or only computes them when there are missing values in a node.
Use median value – If this option is selected, DTREG replaces missing values for predictor variables with the median value of the variable over all data rows. While this option is less exact than using surrogate splitters, it is much faster than computing surrogates, and it often yields very good results if there aren’t a lot of missing values; so it is the recommended option when building exploratory models.